Új hozzászólás Aktív témák
-
#516
 Petykemano
veterán
HSM
#514
Petykemano
veterán
HSM
#514
Petykemano
veterán
Szerintem belefér AM4-be 2 chipletes 12 v 16 magos változat is. Méret, fogyasztás szempontjából mindenképp.
Ha az összekötő IO chipbe még EDramot is tesznek, azzal mindenképp megoldják a CCX-ek közötti kommunikációt és a 32MB/CcX és az edram együtt biztos jelentős mértékben tompíthatja a 2ch DDR terhelését.
Az ár még fontos. Frekvenciát még nem tudunk.. de ha a IF2, és az esetleges L4 kiküszöböli az eddigi CCx felépítésből adódó hátrányokat (latency) akkor már a 1x8 magos változattal is verhető a 9900K és a 2x6 és 2x8 változat is mehet a $400-700, ahol az ilyen magszámú TR1 jelenleg is vannak.Ha van L4, threadripperben biztos kisebb lesz az IO...
Találgatunk, aztán majd úgyis kiderül..
-
#519
Petykemano
veterán
S_x96x_S
#517
Petykemano
veterán
válasz
 S_x96x_S
#517
üzenetére
S_x96x_S
#517
üzenetére
Ez az egész nagyon flexibilis.
A Rome socket kompatibilis lesz a naples-szel. SP3. 8ch DDR4De most, hogy a cpu chipletek készek, bármi máshoz csak az IO chippel kell játszani. Lefelé quarter IO - ian cutress szerint.
Ha már ennyire nagy szám az intel 12ch ddr4 cascade lakeje...
Mennyi esélyét látod annak, hogy az amd később, csináljon egy sp3+/sp4 foglalatot, ami értelemszerűen még nagyobb , és ami 12ch DDR4 (esetleg már ddr5) Memóriát támogat és a lapkán 12 chiplet kapna helyet?
Találgatunk, aztán majd úgyis kiderül..
-
#524
Petykemano
veterán
S_x96x_S
#522
Petykemano
veterán
válasz
S_x96x_S
#522
üzenetére
Arra gondolsz, hogy a kifelé 8 csatornás DDR4 (később DDR5) megtartása mellett lepakolnak a feltételezett eDRAM helyére és/vagy üres helyre 4 stack HBM2-t (lásd Vega20) és HBCC-vel vidáman cachelgetnek 32GB-ban 1-1.2TB/s sávszélesség mellett?
Végülis könnyen lehet, hogy egy ilyen megoldással is könnyen tudnának.etetni 8-nél több chipletet.
Találgatunk, aztán majd úgyis kiderül..
-
#527
Petykemano
veterán
lezso6
#526
Petykemano
veterán
1000 az egész
65-80 között becsülgetik a chiplet méretét, ahhoz képest szemre ~5x nagyobb az IO chip.
75x8=600
75x5=375Ezek nem az én méréseim, becsléseim, csak amik szembejöttek.
Volt egy számítás, ami szerint a zen1ben a CCX 44mm2, kettő együtt mondjuk 90mm2 a maradék ~100 az uncore. Ebből 4 volt a naplesben. A kérdés az, hogy mennyi lehetett a redundancia az önállóan is működőképes zeppelin chipek miatt, amit ki lehetett vágni (usb, northbridge, huzalozás), aminek a helyére esetleg elfér eDRAM.
Ennek persze csak akkor van létjogosultsága, ha a zen2 chiplet mérete inkább nagy. Ha kisebb, az uncore is kicsiTalálgatunk, aztán majd úgyis kiderül..
-
#529
Petykemano
veterán
Simid
#528
Petykemano
veterán
két lehetőség:
- 2 CCX közötti adatkommukáció meggyorsítása úgy, hogy az adatot ne a memórán keresztül kelljen cserélni (ez a feltétezés jelenleg az alapján, hogy a 2 CCX közötti késleltetés magasabb, mint a memóriahozzáférésé)
- memóriahozzáférés gyorsítása hagyományos cache funckióként.De a L4$ létezése még nem bizonyos.
Találgatunk, aztán majd úgyis kiderül..
-
#535
Petykemano
veterán
Simid
#534
Petykemano
veterán
zennél 2x8MB L3$ van
Egyik CCX-től a másikig elég magas a késleltetés
Azért gondoljuk, hogy a CCX-ek közötti elérésben, adattranszferben valahol a memória közrejátszhat, beépülhet, mert az inter-CCX latency általában a mérésekben magasabb, mint a memory latency.,
Itt tökre jól látszik, hogy 8MB felett emelkedik a késleltetés

Egy L4$-sel pedig ezt lehetne kb elérni, amit az 5775C-nál látsz:
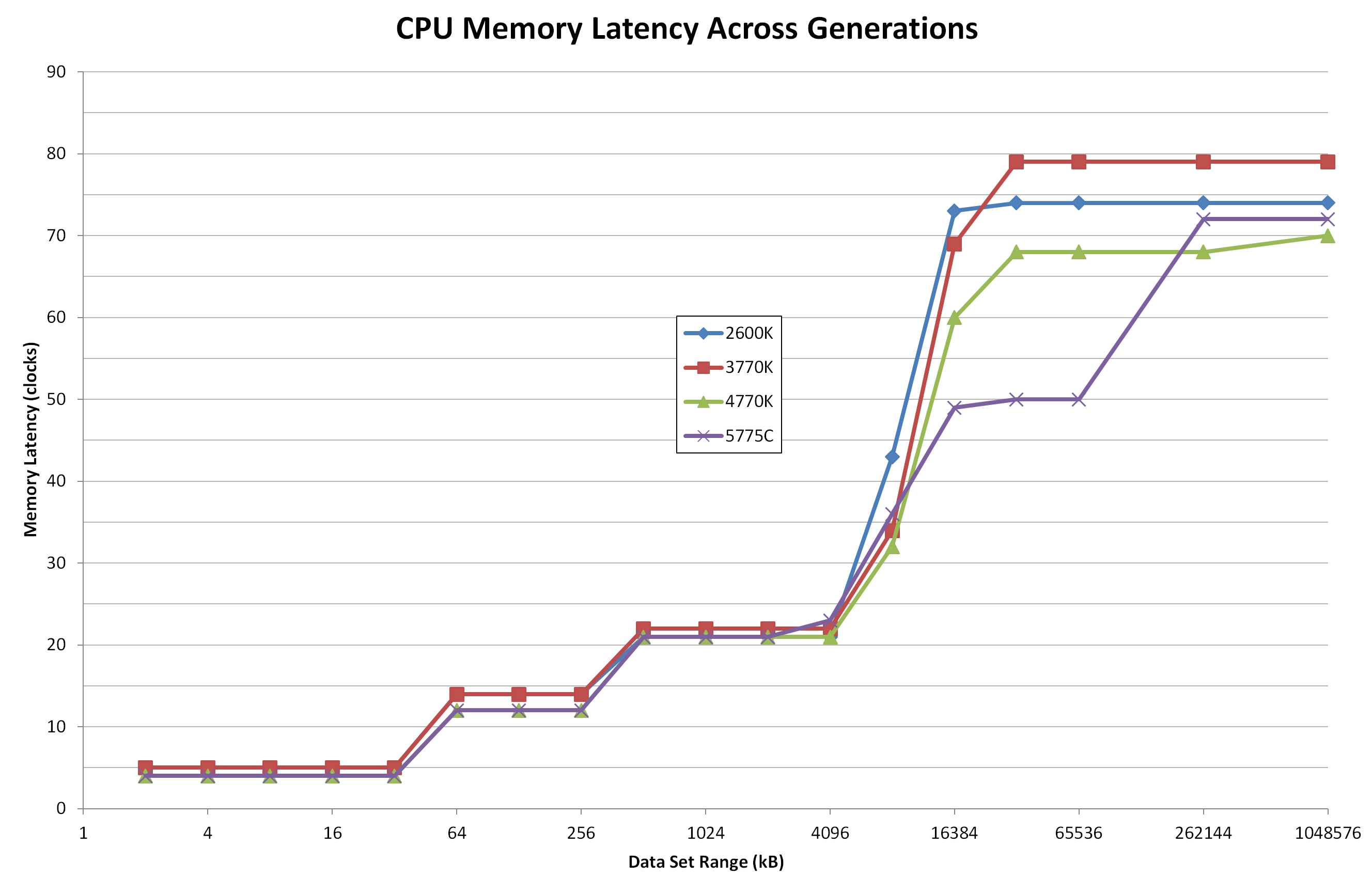
Találgatunk, aztán majd úgyis kiderül..
-
#541
Petykemano
veterán
lezso6
#540
Petykemano
veterán
Annak esetleg látnám létjogosultságát, hogy az egymás melletti chipletek közvetlen módon kommunikáljanak egymással ezzel megtartva valamiféle strukturális visszafelé kompatibilitást az EPYC1-gyel, ahol szintén volt olyan, hogy lapkán belüli magok a lapkán kívüli magokhoz viszonyítva gyorsabb eléréssel rendelkeztek. Így minden optimalizálást, amit az EPYC 1 megkap, áthozható a ROME-hoz is és vica versa, minden ROME optimalizálás értelmet nyer az EPYC1-nél is.
Amúgy looncraz is rajzolt egyet:
![[link]](http://files.looncraz.net/Zen_2_AMD_Rome_IOLayoutTheory.jpg "[link]")
"Decided to throw together a roughly scaled (probably should have been wider and slightly shorter) version of the IO chip using the Zepplin die shot.
This includes everything we know (ahem.. or believe) to exist on the IO die (8 IFOPs, 128 PCI-e lanes, 8 DDR4 channels, etc...) and all of the strange unknown blocks from the Zepplin die. And there was enough room to add 128MiB of L4.. using the L3 from the CCXes directly.
I estimated ~26ns nominal latency to any IFOP from the L4, which is half the latency as to main memory - and with potentially more than double the bandwidth reaching a chiplet (400GB/s). Latency to the L4 from a core would be hard to estimate, but it would be 20~30ns faster than going to main memory, so it's a big win."
Találgatunk, aztán majd úgyis kiderül..
-
#549
Petykemano
veterán
Cathulhu
#548
Petykemano
veterán
válasz
 Cathulhu
#548
üzenetére
Cathulhu
#548
üzenetére
De és ez a csomó késleltetés ez biztos?
Mert ha igen, akkor az meg is adja a választ arra, hogy a következőkben miért is lenne indokolt imterposer használata. Lezso azt mondta, az IF nem széles, nem szükséges az IP, de az IP miközben rövidít, aközben szélesebb buszt is lehetővé tesz. Ha az irány az IF javításán vezet, akkor az IP a későbbiekben elkerülhetetlen.Mindenesetre az jó hasonlat, hogy mintha csak közvetlen memóriaelérés nélküli TR lapkák lennének. Az biztos kolönbség, hogy az IF órajele magasabb kell legyen, ez máris csökkenthet a késleltetesen.
Viszont ha ebben igazad van, az megint csak indkolja, hogy az IO lapkán egy bazi nagy cache legyen, hogy egy útvonal minél inkább megúszható legyen. (Eddig: cpu<->ram, most: cpu<->io), amibe a prefetchelést maga az IO lapka végezze. Pont úgy, ahogy a Vega HBCC-nél láttuk. (Lehet, hogy a technológiát ott csak kipróbálták)
Az, hogy ezt a struktúrát fel lehetne használni gpuknál, nem egyedi gondolat. Sőt, kicsit a 4 Shader engine már eleve ez. De mennyivel jobb lenne minden shader enginet külön gyártani és IF-fel össszekapcsonil? Akár külön célra. Akár válogatva.
(Via)Találgatunk, aztán majd úgyis kiderül..
-
#550
Petykemano
veterán
Petykemano
#549
Petykemano
veterán
válasz
 Petykemano
#549
üzenetére
Petykemano
#549
üzenetére
Ugyanakkor persze annyi különbség van, hogy az SE-k mögötti L2 és HBCC mellett az előttük levő Command processor és Workload distributor is közös. De miért ne lehetne ez az IO chipen?
Fogj meg egy aput, vágd ki belőle a cpu magokat és a CU-kat és kösd hozzá kívülről, skálázd. Voilà.
Ugyanakkor valamiért Dávid Wang mégiscsak azt mondta, ez nem olyan egyszerű nem compute taskok esetén.
(A gput folytassuk a radeon találgatósban)[ Szerkesztve ]
Találgatunk, aztán majd úgyis kiderül..
-
#555
Petykemano
veterán
lezso6
#551
Petykemano
veterán
ITT egy elemzés az Intel i gen1-gen8 "ipc" eredményei és a memória sávszélesség közötti összefüggésről.
A HT eléggé rontja a grafikont... vagyis értelemszerűen egy kezelt szálra kevesebb sávszélesség jut; a HT magok több sávszélességet igényelhetnek.
A videó csak érinti, hogy a CPU magok feldolgozóképességének fejlődésétől elmaradó memóriasávszélesség bővülést a processzorok többszintű cache bevetésével kezelik. Ez kell, hogy adattal tudják elég gyorsan etetni a feldolgozókat. (Ez nem újdonság.Ez az SMT4 érdekes dolog, mert ha megvan a backend 4 szál kiszolgálásához ... de ugye az is hogy? kb 2-3 ILP elérése egyszerű. Most ha jól tudom, 4 integer és 4 128bites fp feldolgozó van. (Bevallom itt már rezeg a léc, hogy fejből mit tudok) tehát mondjuk az SMT4 hatékony kihasználáshoz a zen backendjét meg kéne másfélszerezni? Vagy lehetséges, hogy a 256 bitesre bővítést már eleve úgy hajtották végre, hogy 8 128 hites, amiből 2-2 összeáll 256bites utasítás egy órajel alatti végrehajtására, mint a bulldozerben? Mert mondjuk így elfér az SMT4...
Nade oda akartam kilyukadni, hogy ezt etetni is kell. Akkor itt még durvább cache méretekre és. Sávszélességre lehet számítani.
Illetve ami még segíthet az a tömörítés.
Találgatunk, aztán majd úgyis kiderül..
-
#556
Petykemano
veterán
Petykemano
veterán
mérnök úr most arra jutott, a 420mm2-es io chipbe, ha levonjuk belőle a ddr4 és pcie4 méretét, valamint a zeppelin lapka kitöltő részeit, nem marad hely L4$ számára
Találgatunk, aztán majd úgyis kiderül..
-
#567
Petykemano
veterán
Petykemano
veterán
Találgatunk, aztán majd úgyis kiderül..
-
#588
Petykemano
veterán
Petykemano
veterán
16x16MB L3 => 4C/CCX
?Találgatunk, aztán majd úgyis kiderül..
-
#593
Petykemano
veterán
lezso6
#592
Petykemano
veterán
Az szerintem nem lesz, amíg az ARm ökoszisztéma nem gyorsulja le az x86-ot (nem feltétlenül sebességben, hanem lendületben)
AZ AMD legalábbis pontosan tudja, hogy X86 piacon csak az intellel kell versenyeznie, ha teret kap az ARM, ott legalább féltucat, de inkább tucat versenyző szállhat be a ringbe nem is beszélve arról, hogy a legnagyobb ügyfelek (Amazon, Google, Microsoft, Baidu, stb) meg is tehetik, hogy fejlesztenek maguknak valamit, ami lehet, hogy nem olyan jó, mint az Apple évek alatt összepakolt chipje, de van olyan jó, mint bárki másé a piacon és biztosan olcsóbb összeollózni a kész IP-ket, mint fejleszteni.
Az Arm licencdíja darabszámra megy (nem?), márpedig biztos nem fognak annyi szervercpumagot eladni, mint a mobil piacon. Tehát erre az Armnak még szerintem ki kell találnuia valamit. Talán az interconnect drága?Találgatunk, aztán majd úgyis kiderül..
-
#604
Petykemano
veterán
S_x96x_S
#591
Petykemano
veterán
válasz
S_x96x_S
#591
üzenetére
"Pro: everything just works. Literally. I used my unmodified deployment scripts I use to install a fresh Linode VPS for WikiChip to install and configure the servers. Everything just worked (minor config differences due to using RHEL on AWS and Fedora on Linode, but that's it)."
"The con: it's too damn slow. It does well on the Phoronix Test Suite. It does poorly benchmarking our website fully deployed on it (nginx + php + MediaWiki and everything else involved). This is your "real world" test. All 16 cores can't match even 5 cores of our Xeon E5-2697 v4"
(Src)
Találgatunk, aztán majd úgyis kiderül..
-
#606
Petykemano
veterán
Cathulhu
#605
Petykemano
veterán
válasz
Cathulhu
#605
üzenetére
"As for AMD, in 2016 it launched what remained of the Arm chip it was working on with Amazon, the Opteron A1100 codenamed Seattle. The clue was in the name, we note. Today, AMD is all in with its much more successful Zen-based x86 processors, Ryzen and Epyc, and no one talks about the A1100."
"Here's what we know about the Graviton right now. Its CPU cores are based on Arm's 2015-era Cortex-A72 designs, and are clocked at 2.3GHz. They are 64-bit, Armv8-A, little endian, non-NUMA, and feature hardware acceleration for floating-point math, SIMD, plus AES, SHA-1, SHA-256, GCM, and CRC-32 algorithms.
"Other benchmarks put the Graviton on the same footing as a Qualcomm Snapdragon 835, in terms of single-core performance. CPU benchmarks don't tell the whole story: there's always networking, latency, storage access, and so on, to worry about in the cloud."
Itt még lesz fejlődés.
Találgatunk, aztán majd úgyis kiderül..
-
#608
Petykemano
veterán
Petykemano
veterán
Találgatunk, aztán majd úgyis kiderül..
-
#612
Petykemano
veterán
lezso6
#611
Petykemano
veterán
Az jövő évi amd lineup olyan, hogy tök könnyen lehet rá hihető elképzeléseket felvázolni.
Számomra ennek megfelelően hihető, nagyjából ilyesmire számítanék én is.
Lesz új apu, a Picasso, de arról Fiery eddig végig azt mondta, 14nm.
Ahol szerepel még IGP, zen2 magok mellett, az nyilvánvalóan nem apu, de egy chiplet felépítés mellett ráköthetnek az IO mellé egy Vega 20 (Vega12) lapkát.Más kérdés, hogy az a 14/20CU mire lenne alkalmas 2ch DDR4 sávszél mellett, de ettől függetlenül nem.kivitelezhetetetlen. ebben egyedül az hihetetlen, hogy ezért csupán $20-al kérnének többet.
Máskülönben a frekvenciák hihetők - minden spekuláció arra megy, hogy a kis lapkaméret és az egységes gyártás komoly válogatási lehetőséget biztosít, ami lehetővé teszi a 20-25%-kal jobb frekvenciát elérő lapkák termékké tételez.
Az árak is nagyjából, de csak nagyjából. Talán 10-15%-kal tényleg nyomottabbak, mint amire egy új termék megjelenésekor szokásos. De a 2700X most is $300 körül megy, az 1800X $499-ért debütált. Talán abban igazad van, hogy ha sikerül egyszálon is lenyomni az intelt, akkor azért akár kérhetne többet is - ez szokott lenni a Céges magatartás.Az 5GHz base utolsó sorokat én se hiszem el.
Találgatunk, aztán majd úgyis kiderül..
-
#614
Petykemano
veterán
lezso6
#613
Petykemano
veterán
Igen, ez igaz.
De nem az a nagy kükönbség, hogy anno... volt ez az FSB, Front Side Bus frekvencia, ami ilyen 100-133MHz volt (és akkor 3-4-5MHZ-cel ezt is lehetett húzni.) És akkor a CPU frekvencia az FSB-nek valamilyen szorzata volt. A nagy találmány az integrálás során Gondolom az volt, hogy rövidebb utak mellett magasabb frekvencián tudott menni a belső bus. Ha jól tudom, az Intel ring busa például a magok frekvenciáján megy (ami mondjuk így fura, mert az nem fix)
Ha az AMD megoldotta, hogy az IF, vagyis az IO frekvencia nagy távolságra is tudjon magas frekvencián üzemelni, például a RAM frekvenciáján, ami 1200-1800MHz most, akkor máris 10-15x gyorsabb, mint régen a northbridge. Ha esetleg az IF2-vel megoldották, hogy a RAM névleges frekvenciájával (2400-3600) szaladjon akkor azzal a késleltetéseken is jelentős mértékben javíthatnak, hiszen azonnal el tudják kapni a felszálló és leszállóági adatcsomagot. (Esetleg hasonló trükkel)Mindenesetre érdekes.
Találgatunk, aztán majd úgyis kiderül..
-
#617
Petykemano
veterán
Petykemano
veterán
Guess Ryzen 3700X & 3600X Cinebench score contest
Találgatunk, aztán majd úgyis kiderül..
-
#620
Petykemano
veterán
Simid
#619
Petykemano
veterán
Hmm, esetleg a telefonchipgyártók lemondása által felszabadult gyártókapacitás lehetővé teszi a korábbi piacra vitelt?
A rome shown papermaster azt mondta, számos 7nm design tapeoutja megtörtént addigra.
Ez persze nem erős érv a Januári bejelentésre, de a tavaszi termékeső nem kizárt. Május is tavasz[ Szerkesztve ]
Találgatunk, aztán majd úgyis kiderül..
-
#632
Petykemano
veterán
hokuszpk
#631
Petykemano
veterán
válasz
 hokuszpk
#631
üzenetére
hokuszpk
#631
üzenetére
Engedd meg, hogy megvédjem. Ez a füles, amit kapott lehet tévedés. De ne felejtsük el, hogy elsők között beszélt és tette le a voksát a zen2-rome chiplet design mellett, akkor, amikor még mindenki túl vad elképzelésnek gondolta. (miközben persze mindenki tudta, hogy ez az irány, de mindenki óvatoskodott, hogy hát majd talán később)
Ezen kívül pedig remekül tapint rá a különböző tesztek, hírek, benchmarkok, gyenge pontjaira, vagyis hogy hol van csúsztatás a marketingben (intel TDP, nvidia grafikonok.) Nyilván persze ő sem 100%-osan elfogulatlan, de nem szokta kímélni az AMD-t se.
Ettől függetlenül ez lehet még kacsa. Mások azt gondolják, az AMD direkt és tudatosan szivárogtatott, hogy felmérje, hogyan árazhat - mint afféle ingyenes piackutatás. Én továbbra is azt gondoom, hogy ha bármilyen szándékosság volt ebben és végül nem ez lesz, akkor az csak ártani fog a márkának és kár volt.
Találgatunk, aztán majd úgyis kiderül..
-
#636
Petykemano
veterán
S_x96x_S
#635
Petykemano
veterán
válasz
S_x96x_S
#635
üzenetére
A Twitteren a poszt alatti legújabb találgatások - in response to AdoredTV:
- rendben van, hogy nem logikus New York és Taiwan között utaztatni chipeket összeszerelés céljából, tehát a conzumer piacon a GF IO chip kilőve, de gyártható az a TSMC 16nm-én is. Állítólag a zen1 tapeout úgyis megvolt, nyilván az IO része nem sokat változik.Elgondolkodtató. Mármint nem tényszerűleg ez, hanem az ellenérvek:
Konzumer piacra nem célszerű az IO chipletes megoldás a megnövekedett késleltetés miatt. Meg mert drága?
Praktikusabb 7nm-re tervezniPár évvel ezelőtt még bőven a zen1 megjelenése előtt lehetett hallani az FD SOI-ról. A bulldozerek ugyebár PD-SOI-n készültek eredetileg és a kaveritől jöttek át - már teljesen más elvek szerint tervezetten - 28nm-re.
Az IBM meg 22nm PD-SOI-n gyártott. Szóval akkoriban azt a kérdést vetettem fel ezen jóságokat olvasva, hogy miért nem készít az AMD egy Excavator magokra épített az IBM 22nm-én gyártott cpu-t, hogy áthidalja a nihilt a zen érkezéséig. Akkor azzal oltottak le, hogy (hülye vagy?) senki se készít desktop konzumer piacra CPU-t. Ami a konzumer piacon megvásárolható, az vagy a szerver piacról jön le, vagy a a mobil piacról jön föl. (És ez még a tőkeerős intelre is igaz)Ahogy Besenyő pista bácsi mondta: Na, mi van? Semmi?
Szóval most mi a helyzet ezzel a bölcselettel? Az eddig gyakorlattal ellentétben (amit még az intel is betart) az AMD a maga 10-15%-os piaci részesedésére tényleg lenne olyan balhülye, hogy ezúttal készít desktop konzumer piacra egy(apukkal együtt több) külön lapkát? Ráadásul azon a 7nm-en, amire mindenki azt mondja, hogy ELLLLLLLLLLLLLLLLLLLLLLLLLLKÉPESZTŐEN drága rá fejleszteni?Merthogy ha a Ryzen 3000 nem ugyanazokból a chipletekből áll, mint a Rome, akkor a Ryzen3000 chipeket lényegében sehová máshová nem fogják tudni felhasználni. És a Rome chipletjeinek selejtjét se lehet sehová elszórni, megy a kukába. Threadripperbe ugye nem mehet, mert ott szintén a top bin kell.
Találgatunk, aztán majd úgyis kiderül..
-
#637
Petykemano
veterán
Petykemano
#636
Petykemano
veterán
válasz
Petykemano
#636
üzenetére
Pinky Demon:
"Tovabbra is tartom azt, hogy a sima ryzenek 1 chipletes, max 8 magos integralt I/O-s kiszerelessel jonnek. 2019-ben semmi szukseg es semmi nyomas sincs 8 magnal tobbre asztali gepnel. Akinek tobbre van szuksege, lesz majd TR 16-tol 64 magig. Az kozponti I/O-val jaro extra kesleltetes pont agyonvagna az egyszalas teljesitmenyt, ami itt a legfontosabb (FPS). Es mivel ugy nez ki nem lesz L4 az I/O chipben igy az IF megint a RAM sebesseggel lesz szinkronban ami DDR5 hianyaban ugyanugy vallalhatatlan kesleltetest hozna szerintem, mint a jelenlegi TR-eknel."Hogy miért lenne nem praktikus és illogikus korábbi érák érvelése szerint a külön monolitikus design itt leírtam.
A rome IO chipjében elvileg nincs L4. De ez nem jelenti azt, hogy a ryzen chipekhez ne lehetne olyat készíteni - a drágábbakhoz - amin van. Persze tudom, most úgy fogok dobálózni az IO chipekkel, mintha az ingyen lenne, de a GF14nm-én 8MB L3$ 16mm2 64MB kéne 2 zen2 chiplet mögé, a 128mm2. Ha ehhez hozzáadjuk a IO részeket szerintem 200mm2-ból biztosan kijön. Egy ilyen megoldás $15-ral dobhatná meg a költségeket. De Ne azt nézd, hogy ez abszolút értékben mennyi a megszivárogtatott árakhoz képest. Hanem, hogy ehhez képest mennyivel kerülne többe 7nm-en egy másik chipet tervezni, ami nagyobb is, mint a rome-hoz tartozó zen2 chiplet és a rome-ból hátramaradt hulladékot meg a kukába dobni!
"
Anno bulldozer eraban sem voltak rosszak a dozerek, felso kategoriaban nem versenyeztek, de eros kozepkategoriat megutottek, es mai arakhoz kepest fillerekert lehetett kapni oket. Cserebe hoztak 8 magot 4 helyett, es mire ment vele az AMD? Nem sokra. Most ugyanigy nem latom ertelmet 2019-re a 12-16 magos standard asztali kiszerelesnek. Hasra utok, de ha tudnak kisebb latencyvel mondjuk 10%-ot hozni 1 szalon, az szvsz tobbet jelent egy 8 magos Ryzennel, mint +50% mag. Gamereknel nem fog mindsharet nyerni tobb maggal, ha a legtobb FPS-t a meghatarozo jatekokban intel fog hozni. Jelenleg is aki gamer, az inkabb intelt vesz, hiaba kiegyensulyozottabb valasztas a Ryzen. Tavaly lehetett azt mondani, hogy streamereknek jobb, mert a 8 mag sokkal kiegyensulyozottabb FPS-t hoz mint a 4, de mar az intel sincs lemaradasban itt.Workstation es server piacra ez a strategia tokeletes, epp most veszunk egy 2990WX-et de maris csurog a nyalam, ha bele gondolok mi johet(ne) jovore. Ugyanakkor szerintem nem ez kell ahhoz, hogy az atlag pistit is megnyerjek maguknak, ahhoz az kell, hogy CS:GO-ban, PUBG-ben es Fortniteban is jobb legyen mint az intel, es szerintem az nem fog menni most oszver designnal, mert ahhoz kell az IPC, kell az 5GHz es kelleni fog az alacsony kesleltetes is. Viszont most van szabad 7nm-es kapacitas es forras is vegre, hogy egy kicsit modositott (integralt I/O) lapkat is gyarthassanak.
"Szerintem teljesen más volt az a helyzet, amikor feleolyan erős magokból vehettél 8-at, vagy egységnyi erőt képviselő magokból 4-et. Ehhez képest a Ryzen megjelenésekor úgy dönteni, hogy most veszek 8 magosat, ami magonként 10%-kal gyengébb egy valódi, hosszabb távon gyümölcsöző döntés volt. Nem állítom, hogy ez már beérett, de mivel az intel is elkezdte emelni a magszámot, idővel be fog érni.
Mégegyzer mondom: lehet, hogy a mai intel felhozatallal szemben elégségesnek tűnik, ha ugyanannyi magszámmal rávernek a ma kapható 9900K-ra 10%-ot (mindenféle értelemben) De a ryzen 3000 szerintem nem a 9900K ellen készül, hanem az intel 2019-es felhozala ellen, amiről egyfelől már pletykálják, hogy 10 magos, meg hogy 10nm és minden vonatkozásban előrelépést jelent majd, erősít. Egy 10 magos +50% L1$-t és mindenféle csodákat felvonultató intel újdonság ellen egy 12 magos zen2 szerintem épphogy megütheti +10%-ot.
Abban persze igazad van, hogy ha monolitikus lenne a chip és arra törekednének, hogy minimalizálják a késleltetéseket, akkor akár abból is meglehetne a 8 mag & +10%
Ehhez képest a chiplet, aminek mindenképpen hátránya a lapján kívüli memóriaelérés, a következő előnyökkel kecsegtet:
- nem kell új, nagyobb chipet tervezni 7nm-en. Eddig az AMD mindig megúszósan kezelte a designt, a külön konzumer és pro gpu-ért is hiába könyörgünk.
- Ha egyféle - 8 magos - chipletet használ fel, akkor azok méretüknél fogva rendkívül jól válogathatók
- Ha egyféle - 8 magos - chipletet használ fel, akkor a selejtet fel lehet használni az olcsóbb chipekhez kidobás helyet. Ha két külön design van, akkor egyik selejtjét se nagyon tudod felhasználni.
- Később marha egyszerű lehet a zen2-t átrakni DDR5-ös AM5-re.A video szerint a Ryzen5 és Ryzen7 esetén is 2 zen2 chipletből áll, mindkettőben olyan lapkák, amikben 1 vagy 2 magot le kellett tiltani. Ez tehát abszolút hibás, selejt lapkák felhasználását jelenti. Úgy képzelem, hogy ennek ellenére az 1-1 lapkán üzemelő 4-4 vagy 6-6 mag mellett mind a 32-32MB L3$ aktív lesz. (ilyen ugye a zeppelin lapká felhasználásánál is van, a 4 és 6 magos zeppelin ryzenek rendelkeznek a teljes 16MB L3$-sel)
Ez egy 8 magos selejt chipletből felépűlő proci esetén pont 2x annyi L3$-t jelentene, mint ha monolitikusan készülne maximum 8 maggal. Én azt gondolom, hogy ha a videoban ismertetett felhozatal végül igaznak bizonyul, akkor a Ryzen 5-ök lesznek a legjobb gamer procik.Találgatunk, aztán majd úgyis kiderül..
-
#643
Petykemano
veterán
Simid
#641
Petykemano
veterán
Két referencia eset va, ami késleltetést hoz:
A Zeppelinen belüli CCX-ek közötti kommunikáció, ahol valószínűleg az adat a memórián keresztül utazik, valószínűleg ez és nem az IF okozza a késleltetést, ezért lenne praktikus L4 cache.
A másik a Thredripper, ahol a lapkák közötti kommunkáció még lassabb, mint lapkán belül CCX-ek között és valószínűleg emiatt a közvetlen memóriakapcsolattal nem rendelkező lapka memóriaelérése botrányos.Találgatunk, aztán majd úgyis kiderül..
-
#646
Petykemano
veterán
solfilo
#645
-
#651
Petykemano
veterán
Petykemano
veterán
"Some tech sites are reporting that Gen11 will be Intel's first TFLOPS-class GPU hardware. However, Gen9's (non-mainstream) GT4 implementation (with 72 EUs) was 1.152 TFLOPS. A hypothetical GT4 of Gen11 might have 3.5TFLOPS."
Emellett talán indokolt a 20CU
Találgatunk, aztán majd úgyis kiderül..
-
#664
Petykemano
veterán
Petykemano
veterán
Mit gondoltok, melyik gyártó, vagy chipgyártó fog előrukkolni jövőre arm alapú notebookkal, vagy minipcvel?
Hány magos lesz és milyen TDPvel?
4-8 magos Apple/qualcomm készülék a Y szériás Intel cpukat sztem eléri, sőt lenyomja, legalábbis fogyasztásban. (Sajna ilyen low power a zen se annyira ideális)
Mennyi idő lehet, míg megjelenhetnek 16(-32) magos (A76) minipck 35-45W TDP-vel?Találgatunk, aztán majd úgyis kiderül..
-
#669
Petykemano
veterán
S_x96x_S
#667
Petykemano
veterán
válasz
S_x96x_S
#667
üzenetére
ezt a remek videót néztem meg. Konkrét imformációkat nem tartalmaz, csak elmondja, hogy tulajdonképpen
- hasonló lowpower teljesítményű craptop esetén az armnak a fogyasztása közel fele. (Nem tudom, ez már 7nm arm volt-e)
- olcsóbb is, mint amennyiért az x86-os procikat árulják, ezért a notigyártók nagyon várják a craptop szintre legalább. Minipcre pedig aspiráns lehet a gigabyte
- a natív arm szoftvert nyomja az Apple, a MS, az Amazon
. Tulajdonképpen a google is érdekelt.Azt mondják, hogy az A76 már nagyon összemérhető IPCben a skylakekel, ami esetleg differencia lehet még az azz 5GHz elérése, ami még nyilván előnyt ad a legprémiumabb Intel termékeknek.
Felbukkant az első SMT arm, tehát lehet tovább szélesítemi a feldolgozókat az üresjárat veszélye nélkül.Itt merült föl.bennem a kérdés, hogy mennyi idő lehet magos, míg felbukkan egy 45W 16 magos arm procis szerkezet mondjuk 4GHz turbóval, ami már elegendően jó lehet. A megfelelő számú processzormag használatáról meg a szoftvercégek gondoskodnak, hiszen eleve olyan környezet az arm, ahol nem 1-2, hanem ma már 4-8 magos minden eszköz.
Az AMD ott jön képbe, hogy hát a két legjövédelmezőbb x86 piac a szerver és a notebook, és ezek az armos jövendölesek pont ezeket fenyegetik. A szervert ugye már jövőre is. A qualcomm meg tör fölfelé. Ennek fényébeőn az AMD vajon ráér-e szüttyögni jövőre is 4-6-8 magos procikkal? Vagy valóban indokolt lenne 8-12-16 magos procikkal mindsharet nyerni az.Intel és az arm fölött is?
Találgatunk, aztán majd úgyis kiderül..
-
#673
Petykemano
veterán
lezso6
#672
Petykemano
veterán
Világos, hogy az Apple és a MS is saját magának fog arm szoftvert készíteni , vagy támogatni, nem egy OEM arm minipc vagy notebook számára. (Ebben inkább a Google lehet érdekelt.) De ha macekre es a surfacekre is armon jön szoftver (tegyükhozzá a ms nyilván mimdemt metresz azért, h ne legyen winrt), akkor előbb utóbb összeérhet az az arm gravitáció a szoftvereknél és az olcsón kínált hosszú üzemidejű notebook. Nem?
Találgatunk, aztán majd úgyis kiderül..
-
#681
Petykemano
veterán
Petykemano
veterán
7nm-es szilíciumban gazdag új évet kívánok!
Találgatunk, aztán majd úgyis kiderül..
-
#685
Petykemano
veterán
-
#691
Petykemano
veterán
Petykemano
veterán
1D1212BGMCWH2
BG - 105W
M - AM4
C - 12 core
W - ?
(Apisak)Találgatunk, aztán majd úgyis kiderül..
-
#702
Petykemano
veterán
S_x96x_S
#700
-
#708
Petykemano
veterán
Petykemano
veterán
64C 2.6Ghz 8ch CCIX
Találgatunk, aztán majd úgyis kiderül..
-
#718
Petykemano
veterán
Petykemano
veterán

1) Az tökre adná magát, hogy 1 zen2 lapka mellé kerüljön egy GPU lapka is. 80mm2-be biztos beleférne 20CU valami letisztított megoldásban (FP64). Bár számomra tökre elfogadható lenne, hogy csak vágott darabok kerülnek oda a DDR5 megjelenéséig, ha az IO die-t feljebb toljuk, oda lehet, hogy elfér egy HBM2 és akkor máris kihasználható a 20CU.
De figyelembe véve, hogy mik röppentek fel, hogy nem lesz a kimaradó helyen semmiféle GPU (meglátjuk), azt mennyire tartjátok lehetségesnek, hogy
2) egy nagyobb-hosszabb IO die tartalmazzon eDRAM-ot? A Rome kapcsán is felmerült, de ott végül elvetésre került, mivel a mérete nagyjából kiadja a 4x Zeppelin-2CCX adta helyet.
3) egy olyan IO die kerüljön oda, ami tartalmaz IGP-t. Egy CPU magok nélküli Raven Ridge például?
Találgatunk, aztán majd úgyis kiderül..
-
#722
Petykemano
veterán
Petykemano
veterán
Találgatunk, aztán majd úgyis kiderül..












Új hozzászólás Aktív témák
- Futás, futópályák
- Politika
- Házimozi belépő szinten
- Autós topik látogatók beszélgetős, offolós topikja
- Mesterséges intelligencia topik
- iPhone topik
- Konzolokról KULTURÁLT módon
- AMD Ryzen 9 / 7 / 5 7***(X) "Zen 4" (AM5)
- AMD K6-III, és minden ami RETRO - Oldschool tuning
- Remekül néz ki a szögletes Z Fold6
- További aktív témák...

- Azta Yoga Slim 7 Pro Gamer Procis Ultrabook 14" -30% AMD Ryzen 7 6900HS 16/512 RADEON 2GB 2,8K OLED
- iPhone 15 Pro Max kerestetik
- ASUS ROG Strix G15 G512LI-AL003 (15,6" 144Hz, I5 10300H, 16gb ram, GTX1650TI 4GB, 512gb SSD)
- PNY RTX 3090 24GB GDDR6X XLR8 Eladó! 199.000.-
- Ej-Ha! Lenovo ThinkPad P15 Szép Tervező Vágó Laptop -50% 15,6" i7-10850H 16/512 QUADRO T1000 4GB
Állásajánlatok

Cég: Ozeki Kft.
Város: Debrecen

Cég: Promenade Publishing House Kft.
Város: Budapest