-

GAMEPOD.hu
A legtöbb kérdésre (igen, talán arra is amit éppen feltenni készülsz) már jó eséllyel megtalálható a válasz valahol a topikban. Mielőtt írnál, lapozz vagy tekerj kicsit visszább, és/vagy használd bátran a keresőt a kérdésed kulcsszavaival!

Új hozzászólás Aktív témák
-

Z10N
veterán
Igazad van, csak a hsz-t olvastam el, nem neztem meg a paten-t. Viszont ha a skalar is hozza van szamolva a korabbi CU-nal akkor meg 65 van
 Ezekszerint az utemezesre es vezerlesre komoly hangsulyt fektettek. A hatekonysag pedig az asszimetrikus SIMD-ekbol szarmazhat. Atolvasom majd a folyamatabrakat es a leirast.
Ezekszerint az utemezesre es vezerlesre komoly hangsulyt fektettek. A hatekonysag pedig az asszimetrikus SIMD-ekbol szarmazhat. Atolvasom majd a folyamatabrakat es a leirast.# sshnuke 10.2.2.2 -rootpw="Z10N0101"
-

stratova
veterán
Ez ebben a formában igaz, de nekem úgy rémlik, hogy a legtöbb helyen jelzett core configban ált a SIMD blokkok vector ALU-it számolják és a teljesítmény is g/tflopsban adják meg, ahol az integer alu-t nem számolják bele.
Viszont magyarázat a lényeg:
[0028]
FIG. 4 is a block diagram of a portion of a compute unit (400) with different sizes of SIMD units. It is noted that the compute unit (400) includes various additional components not shown on FIG 4. FIG 4 only shows the portions of of the compute unit (400) relevant to understanding the concepts described herein.[0029]
The compute unit (400) includes a front end fetch and decode logic (402) and one or more arithmetic logic units (ALUs) (404a), (404b). The compute unit (400) also includes a number of different sizes of SIMD units. A two thread wide vector SIMD unit (406) includes two ALUs (408) and has an associated register file (410). A four thread wide vector SIMD unit (412) includes four ALUs (414) and has an associated register file (416). An eight thread wide vector SIMD unit (418) includes two ALUs (420) and has an associated register file (422).[0030]
It is noted that while the compute unit (400) is shown with two scalar ALUs (404) one two thread wide vector SIMD unit (406), one four thread wide vector SIMD unit (412), an one eight thread wide vector SIMD unit (418), the compute unit (400) may be constructed with different numbers of scalar units and the SIMD units without affecting the overall operation of the compute unit (400). Alternatively, SIMD units (406), (412) and (418) may initially have the same width (e.g., each being an eight thread wide SIMD unit) but may be configured (on a demand basis) to deactivate (e.g., gating mechanisms, disabling, powering off, etc.) to have different widths (e.g. a two thread wide, a four thread wide, an eight thread wide SIMD unit, as described above, by deactivating, six, four and zero, respectively, pipes or ALUs in each unit).[ Szerkesztve ]
-
stratova
veterán
[0031]-től kezdődik a magyarázat
By providing a set of execution resources within each GPU compute unit tailored to a range of execution profiles, the GPU can handle irregular workloads more efficiently. Current GPUs (for example, as shown in FIG. 3) only support a single uniform wavefront size (for example, logically supporting 64 thread wide vectors by piping threads through 16 thread wide vector units over four cycles). Vector units of varying widths (for example, as shown in FIG. 4) may be provided to service smaller wavefronts, such as by providing a four thread wide vector unit piped over four cycles to support a wavefront of 16 element vectors.
A +1 skalárhoz:
In addition, a high-performance scalar unit may be used to execute critical threads within kernels faster than possible in existing vector pipelines, by executing the same opcodes as the vector units. Such a high performance scalar unit may, in certain instances, allow for a laggard thread (as described above) to be accelerated. By dynamically issuing wavefronts to the execution unit best suited for their size and performance needs, better performance and/or energy efficiency than existing GPU architectures may be obtained.Példa:
In another example, assume that a wavefront includes 16 threads to be scheduled to a 16 thread wide SIMD unit, and only four of the threads are executing (the remaining 12 threads are not executing). So there are 12 threads doing “useless” work, but they are also filling up pipeline cycles, thereby wasting energy and power. By using smaller (and different) sizes of SIMD units (or vector pipelines), the wavefronts can be dynamically scheduled to the appropriate width SIMD units, and the other SIMD units may be powered off (e.g., power gated off or otherwise deactivated). By doing so, the saved power may be diverted to the active SIMD units to clock them at higher frequencies to boost their performance.Infó:
The smaller width SIMD units may be, for example, one, two, four, or eight threads wide. When a larger thread width SIMD unit is needed, any available smaller thread width SIMD units may be combined to achieve the same result. There is no performance penalty if, for example, the wavefront needs a 16 thread wide SIMD unit, but the hardware only includes smaller thread width SIMD units.In some embodiments, the collection of heterogeneous execution resources is shared among multiple dispatch engines within a compute unit. For instance, rather than having four 16 thread wide vector units, four dispatchers could feed three 16 thread wide vector units, four four thread wide vector units, and four high-performance scalar units. The dispatchers could arbitrate for these units based on their required issue demands.
-
stratova
veterán
Szerk. hibás volt a feltételezés, az által hogy ha elegendő kevesebb ALU-t aktiválni emelhetik az órajelet is adott fogyasztáson belül:
By using smaller (and different) sizes of SIMD units (or vector pipelines), the wavefronts can be dynamically scheduled to the appropriate width SIMD units, and the other SIMD units may be powered off (e.g., power gated off or otherwise deactivated). By doing so, the saved power may be diverted to the active SIMD units to clock them at higher frequencies to boost their performance.
[ Szerkesztve ]
-
#18999
 Malibutomi
nagyúr
gbors
#18998
Malibutomi
nagyúr
gbors
#18998
-

Abu85
HÁZIGAZDA
Az AMD oldalán is lesz jelentős. De az órajelemelésnek van egy hátránya, mégpedig a fogyasztás. Sokkal kézenfekvőbb több ALU-val és kisebb órajellel elérni a ugyanazt a teljesítményt, mert az kisebb fogyasztást eredményez. A GCN memóriamodellje jóval újabb, így jóval tovább skálázódik az alapdizájn. Valószínűleg ezeket a trükköket az AMD is be fogja vetni akkor, amikor a dizájn skálázhatósága a végét fogja járni. Most még elég ha megélnek abból, hogy tranzisztorkímélőbb az alapkonstrukciójuk.
Senki sem dől be a hivatalos szóvivőnek, de mindenki hisz egy meg nem nevezett forrásnak.
-

Oliverda
félisten
Lesz, csak éppen nem kellenek hozzá plusz tranzisztorok.

Abu85:
"Sokkal kézenfekvőbb több ALU-val és kisebb órajellel elérni a ugyanazt a teljesítményt, mert az kisebb fogyasztást eredményez. A GCN memóriamodellje jóval újabb, így jóval tovább skálázódik az alapdizájn. "
Kézenfekvőbb, viszont jól láthatóan egyáltalán nem könnyű. A Fiji konkrétan pocsékul skálázódik. ~45%-kal több SP, 34%-kal magasabb mem. sávszél, ehhez képest pedig játékok alatt legjobb esetben van 20% a Fury X és a 390X között. Nem véletlen, hogy nem fogják tovább növelni az SP-k számát, hanem inkább kihasználják a FinFET előnyeit, és emelik az órajeleket.
"Minden negyedik-ötödik magyar funkcionális analfabéta – derült ki a nemzetközi felmérésekből."
-
Abu85
HÁZIGAZDA
Attól függ, hogy melyik programban. Ha ezt a rendszert tényleg belerakják hardveres rásegítéssel, mint ahogy azt az utóbbi hetekben erősen pletykálják, akkor szétverhet mindent az olyan programokban, amely nem jól optimalizál a háromszögek kivágására, mivel itt jóval kevesebbet fog dolgozni a Polaris, mint minden más.
[ Szerkesztve ]
Senki sem dől be a hivatalos szóvivőnek, de mindenki hisz egy meg nem nevezett forrásnak.
-
Abu85
HÁZIGAZDA
Én a hogyanra vagyok kíváncsi, mert ez azért nem egyszerű. Nem véletlen, hogy áteresztik a GPU-k a fals pozitívokat. Bitang komplex hardver kell azok kiszedésére, ami nem biztos, hogy megéri a tranzisztort. De ha megcsinálják tényleg jóra, akkor azzal durván alázni fognak, különösen a minimum fps-ben.
(#19073) rocket: 350 dollártól van performance.
[ Szerkesztve ]
Senki sem dől be a hivatalos szóvivőnek, de mindenki hisz egy meg nem nevezett forrásnak.
-
-
stratova
veterán
De miért ne duplázhatnák most ők is a ROP-ot a la Maxwell?
Bár nekem a 256 bit GDDR5 még mindig kicsit sovány ha csak nem 7 GHz-en ketyeg, de a minták nem ennyin mentek. Ha mindezt meglépnék akkor illene valahol, GTX 980 szinten lennie a kisebbik Polaris 10-es kártyának (Videocardz-nak honnan jött a 4 variáns?), ha minden klappol és a color compression is legalább Maxwell szinten van.[ Szerkesztve ]
-
Abu85
HÁZIGAZDA
Tuti a 384 bit, ha erre gondolsz. Maga Raja Koduri ismerte el, hogy a Tongában 384 bites busz van 32 ROP egységgel. A GCN-t már a kezdetek óta úgy tervezik, hogy külön van választva a ROP és a memóriacsatorna.
[ Szerkesztve ]
Senki sem dől be a hivatalos szóvivőnek, de mindenki hisz egy meg nem nevezett forrásnak.
-
stratova
veterán
Pedig már a hivatalos közlés előtt is látszott egyes oldalak/fórumok elemzése szerint, hogy eredetileg 6x64 bites csatornával készült:
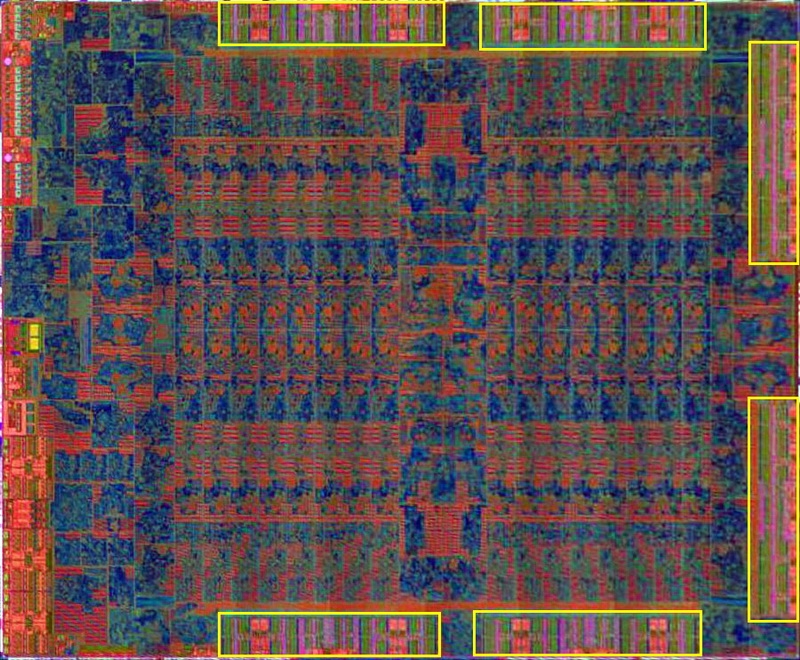
De ha nem lenne független, hogyan készíthetnek volna 1280:80:32 256 bites Pitcraint-t és 2048:128:32 384 bites Tahitit?
Gondolom akkor vetették volna be, ha készül egy asztali GTX 960 Ti, aminek "ideális alap" lett volna a GTX 970M (10 SMM 1280 SP 80 TMU 48 ROP 192 bit GDDR5). Bár itt Tonga 32 ROP egysége még mindig karcsú lett volna.
[ Szerkesztve ]
-
Abu85
HÁZIGAZDA
A konkrét fotó miatt kérdezgették az AMD-t, hogy most az a 6 darab blokkból kettő micsoda. Egy ideig terelt az AMD, de aztán Raja elmondta, hogy valóban igaz az a pletyka, hogy a Tonga 384 bites, de mivel nem tudtak neki megfelelő pozíciót találni a termékskálán, így 256 bitesként adták ki az összes verziót.
(#19208) Petykemano: Mert sávszélességre van nagyobb szükség.
[ Szerkesztve ]
Senki sem dől be a hivatalos szóvivőnek, de mindenki hisz egy meg nem nevezett forrásnak.
-
Abu85
HÁZIGAZDA
Ilyenek előfordulnak, amikor a 90 fokkal el kell forgatni. Ilyenkor nem terveznek külön blokkokat a memóriavezérlőhöz, hanem az eszközszint szerinti blokkok szempontjából a síkon nem egymás mellé, hanem egymás fölé helyezik őket. Ezek valójában ugyanolyanok egységek, csak másképp vannak fizikailag elrendezve. Ha nem így csinálnák, akkor az eszközszint szempontjából kétféle memória I/O-t kellene tervezni. Egy normált és egy 90 fokkal elforgatottat.
Biztos arra van szükség. Csak túl közel került volna a 390-hez egy 384 bites Tonga.
A GCN-es alap egészen más teljesítménytartományra tervezett rendszer, mint a fermis alap, amire az NV épít. Az NV nem tud 6 GPC blokk fölé menni, míg az AMD simán tud skálázni a GCN-nel 12 hasonló blokkig is.[ Szerkesztve ]
Senki sem dől be a hivatalos szóvivőnek, de mindenki hisz egy meg nem nevezett forrásnak.
-
#19235
Malibutomi
nagyúr
gbors
#19232
Malibutomi
nagyúr
-
Én kb. januártól úgy gondolom, hogy nem érdemes már 28nm-es kártyát venni, csak ha valami nagyon jó deal van. De ha valakinek sürgős, akkor ez van - 1070 normális áron még azért nem holnap lesz itthon.
Hali!
mit tippelsz mikortól fogja a GTX970 használtpiaci árára rányomni a 1070 a bélyegét?
J.
-
stratova
veterán
Szerintem már most látszik, hogy marad az eddigi gyakorlat. Már GP200-nál borítékolható volt, hogy Nv újból magas órajelre AMD nagy tranzisztorsűrűségre gyúr, utóbbi esetben legfeljebb az "SP/ALU-lekapcsolgatással" tudnak órajelet nyerni. AMD-nél mindemellett csak a ROP-okat és a memóriát kéne gatyába rázni szvsz. De megint nagyobb "ALU számú" alacsonyabb órajelű lapkával mennek a konkurenciának.
[ Szerkesztve ]
-
#19271
Malibutomi
nagyúr
gbors
#19269
Malibutomi
nagyúr
Van benne valami, meglatjuk mit tudnak belepakolni. Ha igaz a ketszeres tranzisztorsuruseg a 28nm-el szemben, akkor igazabol nagyobb mint egy hawaii chip. Ha tudnak hatekonysagot es orajelet novelni, akkor siman gyorsabb is lehet.
De nem varok csodat azert, majd meglatjuk.#19270) stratova
Sajnos a marketing meg mindig nem erosseguk, maxwell utan lathattak volna hogy verpistikeknek fontosabb a nagy szam az orajel mellett mint a tenyleges teljesitmeny.
Most is sokan mar maguk ala csinaltak hogy 1700mhz vege az amd-nek.[ Szerkesztve ]
-

füles_
őstag
Azt már biztosra lehet tudni hogy a Polaris10 nem fog GDDR5X-szet használni?Mert ha fog használni ez megmagyarázná azt a pletykát,miszerint júniusban csak az X nélküli 480 jön.És így érthető lenne hogy hogyan lehet lassabb 15-20%-kal a csonkított P10 mint a teljes értékű,miközben csak 4 CU van letiltva benne
[ Szerkesztve ]
-

#45185024
törölt tag
-
#19278
Malibutomi
nagyúr
gbors
#19269
Malibutomi
nagyúr
gbors szamolgattam egy kicsit, es lehet tevedek, de szerintem nem lesz olyan kozel a P10 es a GP104 tranzisztorszamban. Tul nagy a meretkulonbseg.
Ha jol szamolok az 1080 (330mm2 - 7.2milliard) 16nm-en 63%-al tobb tranzisztor/mm2 mint a 980 (391mm2 - 5.2 milliard) 28nm-en. Ha ezt a P10 meretere (232mm2) vetitem a Hawaii-al osszevetve (438mm2 - 6.2 milliard) akkor csak 5.2 milliard jon ki.
De ha azt nezem mennyivel surubb az AMD az NV-hez kepest, akkor a 290x (438mm2 - 6.2 milliard) a 780ti-hez kepest (533mm2 - 7.2 milliard) kb 5%-al, a 980-hoz (391mm2 - 5.2 milliard) kepest 6%-al surubb.
Ha ezt vetitem a Polaris meretre akkor is csak 5.3 milliard jon ki.Megtenned hogy utanaszamolsz, mert siman lehet hogy tevedek.
[ Szerkesztve ]
-
#19284
Malibutomi
nagyúr
gbors
#19283
Malibutomi
nagyúr
Na akkor ott tartunk, hogy gyakorlatilag barmi lehet, csak talalgatni tudunk.
A kulonbozo node igaz. En ebbol indultam ki ami alapjan a 16 es 14nm kozott nagyon minimalis a kulonbseg meretben, persze ettol lehet elteres hogy milyen suruseget tudnak kihozni belole.

Egyebkent a 16nm FF+-ra is azt mondja a TSMC hogy dupla tranzisztor suruseget tud a 28nm-el szemben. Hogy ez igaz, es az NV nem akart olyan suru chipet, vagy tulzas volt (esetleg mindketto, azt nem tudom.
"Én 310 mm2-re emlékszem a GP104 kapcsán, és ezt "húztam le" 14nm-re. Éltem azzal az optimista feltételezéssel, hogy a 16nm és a 14nm között méretarányos a skálázódás, ekkor a GP104 14nm-en 237mm2."
Ez a 237mm2 meret hogy jott ki? Nem kotekedes, en elismerem hogy csak jozan paraszti esszel szamolgatok, amugy nem ertek hozza
Szoval hatha tanulok valamit [ Szerkesztve ]
-
#19289
Malibutomi
nagyúr
gbors
#19288
-
füles_
őstag
Órajelekről már voltak információk: volt már 1050 és 1150MHz is
Ha szerinted 1GHz/2304 ALU/256 bit/32 ROP esetén egyes helyeken elpicsázná a Fury X-szet akkor 1,15GHz/2560 ALU/256 bit/64 ROP esetén már illene hoznia az 1080-at nem?Meglepődnék ha csak 32 blending egységgel hoznák ki a P10-et,azon még jobban meglepődnék ha a P10-ből akármilyen módon kitudnák facsarni az 1080 teljesítményét Félreértés ne essék,nem várok a P10-től 1080 teljesítményt,ha hozni fogja az 1070-et már több mint elégedett leszek 
Amúgy nem úgy volt hogy a nem látható háromszögek kiszűrése inkább csak a minimum FPS-t növeli?[ Szerkesztve ]
-
#19296
 Petykemano
veterán
gbors
#19293
Petykemano
veterán
gbors
#19293
Petykemano
veterán
A 14 és 16 ha a valóságtól nem is teljes mértékben elrugaszkodott értékek, de valójában csak marketing célokat szolgáló elnevezései a gyártástechnológiának.
A két különböző gyártástechnológia méret és sűrűség össszehasonlítására való felhasználás esetén épp ezért lehet, hogy félrevezető eredményekre vezet.
Érdekelne a számításod az elnevezések helyett a tényleges (legalábbis ismert) számok alapján. (Anélkül, hogy belebonyolódnék magába a számításba)
Találgatunk, aztán majd úgyis kiderül..
-
Abu85
HÁZIGAZDA
Lesz GDDR5X-es Polaris 10. A gond igazából azzal van, hogy a Micron olyan mennyiséget, amivel piacot is lehet szerezni csak Q3-tól tud biztosítani. A gyártóknak szükséges 12-14 Gbps-os lapka még a kísérleti gyártás fázisában van. A 8 Gbps-os viszont tömeggyártás alatt. Arra lehet építeni nagy mennyiségben is.
Egyébként a GDDR5X-et nem támadom, de értelmetlen irány, mert semmilyen memóriával kapcsolatos problémát nem old meg.
[ Szerkesztve ]
Senki sem dől be a hivatalos szóvivőnek, de mindenki hisz egy meg nem nevezett forrásnak.
-
Abu85
HÁZIGAZDA
Ez azért bonyolultabb ennél, mert nagyon sok tényező befolyásolja a tranzisztorszámot. Például az AMD-nél a GloFo egy kérdőjel a HDL és a HPL szempontjából, mert a TSMC-hez csak HDL van portolva, de a GloFo esetében használható HPL dizájn is, ahogy használják is az IGP-ik. Ez azért döntően befolyásolja a tranyósűrűséget.
Senki sem dől be a hivatalos szóvivőnek, de mindenki hisz egy meg nem nevezett forrásnak.
-
Abu85
HÁZIGAZDA
A lényegét kérdőjelezem meg. A GDDR5X ugyanazokat a problémákat hordozza, amit a GDDR5 és előtte a többi memória. Ergo ugyanúgy megy a memóriafal jelensége felé. Az önmagában nem jó, hogy kísérleti gyártáson lévő memóriákat kell használni a VGA-khoz, és még úgy is csak 10 GHz az effektív órajel. A kísérleti gyártás nagy problémája, hogy nagyon korlátozott az ellátás. A tömeggyártás alatti GDDR5X memóriák viszont valószínűleg nem voltak jók. Talán nagyobb volt az interferencia, mint amire számítottak. Ez azért valószínű, mert az interferencia általános probléma volt a Micronnál 45 cm-es NYÁK alatt, jó persze azok 12+ GHz-es memóriák voltak. Elképzelhető, hogy 10 GHz az a határ, ahol még kezelhető megfelelő árnyékolással a jelenség. Az is kérdés, hogyan viselkedik 256+ biten.
[ Szerkesztve ]
Senki sem dől be a hivatalos szóvivőnek, de mindenki hisz egy meg nem nevezett forrásnak.
-
#00137984
törölt tag
R9 480 elméletileg egy szintet léphet felfelé teljesitményben. Én már közel másfélszeres erősödést is megelölegeztem a friss driverek kiadása után. Mire nem is lesz ez elég... R9 390X szinten megint csak olyan fél éven keresztül fog kitartani a lelkesedés, aztán már nem én leszek az országútak istene... [link]
-
#19750
Malibutomi
nagyúr
gbors
#19749
-
#19758
Petykemano
veterán
gbors
#19749
Petykemano
veterán
2304@1266mhz@120w = 390x
Valóban elég sovány fejlődés, mégha feleakkora területből jön is ki. (Fele áron)Viszont a 2560 mag ha elmegy 1400-1500Mhz-en, plusz még a drágának tűnő architekturális újítások (ha nem merülnek ki a magasabb frekvenciában és/vagy alacsonyabb fogyasztásban) túllőnek minden racionális elképzelésen.
Találgatunk, aztán majd úgyis kiderül..
-

Yutani
nagyúr
Na igen, ha racionális vagyok, akkor nem R9 380-at veszek, hanem GTX 960-at a fogyasztás miatt, ráadásul az NV drivere nem terheli annyira a procit, mint az AMD-jé, így egy 2 modulos FX-hez jobb is lett volna a 960. De úgy vagyok, hogy AMD gépbe AMD VGA. Tudom, fazzság, de ez a heppem.

A lekapcsoló ventinek nem vagyok híve. Év elején, amikor még S1155 konfigom volt, az alaplapon a PCH pont a PCIe alatt volt. Amikor az MSI GTX 960 Gaming bekerült, felszökött a PCH hőmérséklete vagy 15 fokot, mivel a termelt hőt előtte a HD 7870 elszívta, de a 960 leálló ventije már nem. Persze megoldás erre az oldalsó ventilátor, amit azóta megléptem az AMD északi híd és az R9 380 miatt.
#tarcsad
-
#00137984
törölt tag
Ha alacsonynak mondható 1.25-1.35 GHz-es GPU órajelek és főleg 32ROP kerül az R9 480-ra, akkor nem a 2304 shader miatt fogok feljebb vagy máshol nézelödni. GDDR5 változat az X nélkül, a 4 GB vagy 8 GB videómemória akkor már még kevésbé számitana. Mondjuk az R9 380 esetében a 2GB vs 4GB videómemória nem volt mindegy, mert a Tonga GPU hozott vele némi gyorsulást egy-két játékban. 8GB videómemória.. ez már dőfi ! DVD méretű helyen már elég ritkán fogunk LOADING felirattal találkozni a játékokban.
[ Szerkesztve ]





 Ezekszerint az utemezesre es vezerlesre komoly hangsulyt fektettek. A hatekonysag pedig az asszimetrikus SIMD-ekbol szarmazhat. Atolvasom majd a folyamatabrakat es a leirast.
Ezekszerint az utemezesre es vezerlesre komoly hangsulyt fektettek. A hatekonysag pedig az asszimetrikus SIMD-ekbol szarmazhat. Atolvasom majd a folyamatabrakat es a leirast.



![;]](http://cdn.rios.hu/dl/s/v1.gif)












Új hozzászólás Aktív témák
A topikban az OFF és minden egyéb, nem a témához kapcsolódó hozzászólás gyártása TILOS!
MIELŐTT LINKELNÉL VAGY KÉRDEZNÉL, MINDIG OLVASS KICSIT VISSZA!!
A topik témája:
Az AMD éppen érkező, vagy jövőbeni új grafikus processzorainak kivesézése, lehetőleg minél inkább szakmai keretek között maradva. Architektúra, esélylatolgatás, érdekességek, spekulációk, stb.
- Motoros topic
- Nagyrobogósok baráti topikja
- Megérkezett a Google Pixel 7 és 7 Pro
- Milyen okostelefont vegyek?
- Multimédiás / PC-s hangfalszettek (2.0, 2.1, 5.1)
- EA Sports WRC '23
- Asztrofotózás
- Ki hogy szokta levezetni az idegességét?
- A fociról könnyedén, egy baráti társaságban
- eMAG vélemények - tapasztalatok
- További aktív témák...

Állásajánlatok

Cég: Alpha Laptopszerviz Kft.
Város: Pécs

Cég: Ozeki Kft.
Város: Debrecen